Mais sobre sequências de elementos e fatias
Listas, tuplas e strings
Listas e tuplas são duas das mais comuns coleções ordenadas de itens no Python. Strings (cadeias de caracteres) ou textos, para simplificar, são coleções ordenadas também, contendo caracteres (letras, emojis ou glifos em geral). No meio do código, uma tupla pode ser construída com elementos separados por vírgulas, e se necessário parenteses, ( ,), a lista é feita com colchetes [ ,], e um string com aspas, simples ' ', duplas " " ou trincas de aspas simples ou duplas (''' ''' e """ """).
anos = [1968, 1976, 1980, 1994] # uma lista de números
lista_de_nomes = ['Bernardo Fontes', 'John Cleese', 'Georg Nees'] # uma lista de strings
ponto = (23, -45) # uma tupla com números representando coordenadas de um ponto
pontos = [(10, 10), (100, 10), (100, 90), (20, 100)] # uma lista com tuplas de números dentro!
pontuacao = ".,:;()?" # um string
versao = "3.7a" # ou outro string
Uma lista permite que seus itens ou elementos sejam alterados, adicionados, removidos, ou, como um todo, os itens podem ser reordenados. Dizemos que listas são mutáveis. Já uma tupla ou um string não podem ter elementos adicionados, removidos e também não podem ser reordenados, dizemos que são estruturas imutáveis. Se for necessária uma correção, sempre podemos criar tuplas e strings novamente com a alteração em substituição à coleção original.
Saiba que tuplas são mais ‘econômicas’ em termos computacionais (por exemplo, em casos de grande quantidade de dados, gastam menos memória) e são bastante usadas quando a ordem dos elementos tem significado, por exemplo podemos fazer uma tupla com os dados para a construção de um círculo:
c = (100, 50, 40) # os númereos representam x, y, diâmetro respectivamente
Não faz sentido nenhum reordendar, acrescentar ou remover elementos de uma tupla como essa que descreve o círculo, ela funciona como um "registro" (record em inglês) cujos campos não tem nomes explícitos mas tem significado pela posição. Se você precisar alterar o círculo pode recriar a tupla que o descreve.
Número de itens, tamanho ou comprimento da sequêcia (length): len()
Podemos obter o tamanho, isto é, o número de itens, de praticamente qualquer estrutura de dados em Python (ordenada ou não) usando a função len(). Por exemplo:
lista_de_nomes = ['Bernardo Fontes', 'John Cleese', 'Georg Nees']
print(len(lista_de_nomes)) # exibe 3
ponto = (23, -45)
print(len(ponto)) # exibe 2
n_paises = len(codigos_de_pais) # lista baseada em https://www.iso.org/obp/ui/#search
print(n_paises) # exibe 249
Consultando individualmente itens de uma sequência
Quando temos uma lista, tupla ou outra coleção ordenada, podemos consultar seus itens pelo índice de posição com a notação [i], sendo que a primeira posição é a posição de índice 0, e a última é a que tem como índice o número total de itens menos 1:
numeros = (2, 4, 6, 8, 10, 12, 24, 2048) # alguns números
print(numeros[0]) # 2 o primeiro número
print(numeros[1]) # 4 o segundo número
print(numeros[len(numeros) - 1]) # 2048 o último
print(numeros[-1]) # com o índice -1 também temos o último item, 2048!
print(numeros[8]) # ERRO: índice 7 é o último! IndexError: index out of range: 8
Strings como sequências de itens
Uma vez que Python trata strings, texto, como um espécie de sequência, é possível iterar, isto é, realizar uma ação para cada caractere de um string:
nome = 'Guido'
for letra in nome:
print(letra)
# resultado no console é:
# G
# u
# i
# d
# o
Podemos consultar o comprimento de um string usando len(texto) e o caractere em uma certa posição com a notação texto[índice]:
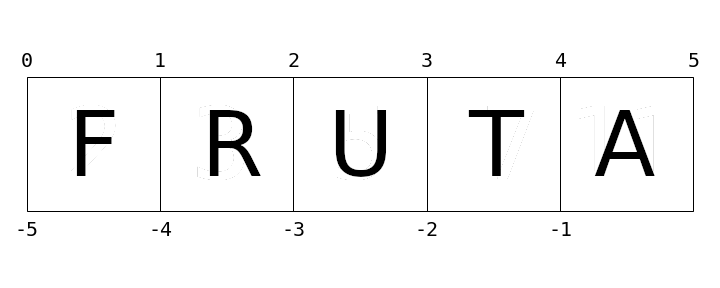
palavra = 'FRUTA'
print(len(palavra)) # 5
print(palavra[0]) # 'F' a primeira letra
print(palavra[1]) # 'R' a segunda letra
print(palavra[-1]) # 'A' a última letra - posição (len(frase) - 1)
print(palavra[5]) # IndexError: index out of range: 5
Alterando itens
Estruturas mutáveis como listas, podem ter seus itens alterados, incluídos ou removidos.
lista = [1976, 1980, 1988, 2013]
print(lista[2]) # o resultado é o terceiro número (índice 2):
# 1988
lista = [1976, 1980, 1988, 2013]
lista[2] = 1994 # muda o terceiro item (índice 2)
print(lista) # resultado:
# [1976, 1980, 1994, 2013]
lista.append(2020)
print(lista) # resultado:
# [1976, 1980, 1994, 2013, 2020]
del lista[1] # remove o segundo item (índice 1)
print(lista) # resultado:
# [1976, 1994, 2013, 2020]
a = lista.pop() # remove e nos entrega ('devolve') o último item
print(a) # 2020
print(lista) # [1976, 1994, 2013]
b = lista.pop(1) # remove e devolve para atribuição o segundo item
print(b) # 1994
print(lista) # [1976, 2013]
Tuplas e strings são imutáveis, não permitem esses tipos de operação.
Fatiamento (slicing)
Com a notação [inicio:parada:passo] podemos obter uma subsequência ou fatia (slice) de uma sequência. É possível deixar vazias as posições dessa notação, na forma [inicio:parada], [:parada], [inicio:], ou ainda [::passo], entre outras. Veja alguns exemplos:
nums = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1) # uma tupla
print(nums[1:9:2]) # início: 1, parada: 9 (não incluso), passo: 2
# resultado: (1, 3, 5, 7)
nome = 'Saskia Freeke'
a = nome[:6] # do início até a sexta letra, sétimo item (6) não incluso.
print(a) # resultado: 'Saskia'
b = nome[7:] # início na oitava posição (7) até o final.
print(b) # resultado: 'Freeke'
print(nome[1::2]) # segunda posição até o final, de duas em duas.
# resultado: 'akaFek'
print(nome[:11:2]) # início até a décima, de duas em duas.
# resultado: 'Ssi re'
Cópias e inversões
Uma fatia que é uma cópia da sequência
A notação [:] (fatiamento com início e parada vazios) produz uma cópia completa da sequência. O que é especialmente útil para sequências mutáveis. Uma vez que a atribuição, por exemplo de uma lista, a mais de uma variável não produz cópias, mas sim varios nomes apontando para a mesma lista na memória do computador:
a = [0, 1, 2, 3, 4]
b = a
del b[3] # remove o quarto item da lista
print(b) # [0, 1, 2, 4] como esperado
# mas, talvez você se surpreenda!
print(a) # [0, 1, 2, 4]
a = [0, 1, 2, 3, 4]
b = a[:] # cria uma cópia nova da sequência
del b[3] # remove o quarto item da lista `b`
print(b) # [0, 1, 2, 4]
print(a) # [0, 1, 2, 3, 4]
Invertendo uma sequência
Uma das maneiras mais comuns de se obter uma cópia invertida de uma sequência é utilizando a notação de fatiamento, com o início e parada vazios (do início ao final) mas com o passo -1, o que fica [::-1] como nos exemplos abaixo:
print("Alexandre"[::-1]) # exibe: erdnaxelA
a = [0, 1, 2, 3, 4]
b = a[::-1]
print(b) # exibe: [4, 3, 2, 1, 0]
c = reversed(a) # você também pode usar reversed()!
print(c) # exibe <reversediterator object at 0xNN> onde NN varia
print(list(c)) # exibe: [4, 3, 2, 1, 0]
Enumerando os itens de uma coleção
Ao iterarmos por uma coleção, pode ser útil obter ao mesmo tempo que o item, um contador. No caso de sequências ordenadas, como listas e tuplas, esse contador é o índice da posição do item na sequência. Isso é chamado de enumeração, e fazemos isso usando a função embutida enumerate().
for «variável_para_índice», «variável_para_item» in enumerate(«coleção»):
«corpo»
Veja usado no contexto do exemplo anterior.
def setup():
size(400, 400)
pontos = [(50, 50), (300, 370), (200, 50), (150, 150)]
for i, ponto in enumerate(pontos):
# enumerate vai nos entregar uma sequência de tuplas:
# (índice, item_da_coleção)
x, y = ponto
fill(255)
ellipse(x, y, 5 + i * 5, 5 + i * 5)
# legenda em um string no formato «i: x, y»
legenda = str(i) + ": " + str(x) + ", " + str(y)
fill(0)
text(legenda, x + 15, y)
# Você também pode encontrar escrito assim: «for i, (x, y) in enumerate(pontos):»
# E a construção «legenda = "{}: {}, {}".format(i, x, y)» para o formar texto
# o método .format() injeta valores passados como argumentos em posições marcadas com {}

Uma utilidade de enumerar, pegar pares de itens
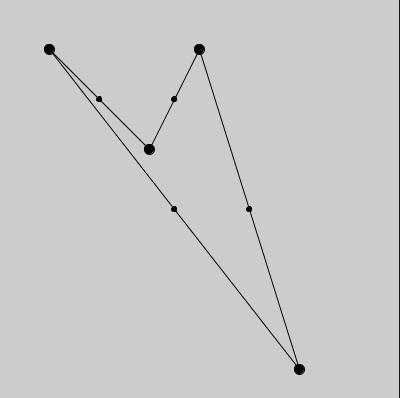
def setup():
size(400, 400)
fill(0) # preenchimento preto esconde a treta da linha sobrepondo
pontos = [(50, 50), (300, 370), (200, 50), (150, 150)]
for i, ponto in enumerate(pontos): # (índice, ponto) para cada ponto de `pontos`
xa, ya = ponto
ponto_anterior = pontos[i - 1] # pega o último item da lista quando i é 0
xb, yb = ponto_anterior
circle(xa, ya, 10)
# desenha linha entre os dois pontos
line(xa, ya, xb, yb)
# desenha círculo menor entre os pontos
circle((xa + xb) / 2, (ya + yb) / 2, 5)
Assuntos relacionados
- Repetição com
for- o primeiro contato com este assunto da iteração. - Mais sobre listas e seus métodos (inserir itens no meio, encontrar o índice de um item e muito mais)
- Arrastando vários círculos
- Mais sobre strings e métodos dos objetos string